高可用性かつスケーラブルなKubernetesクラスターを運用するときに気を付けたいこと
お仕事でプリセールスをしているため、お客様やSIパートナー様といっしょに「ぜったいにサービスを止められないシステム」について議論することが多くあります。
一方、クラウドはオンプレに比べてスケーラブルな構成をとることが得意です。したがって、ユーザーの利用が時間的にばらつきがあるシステムやスパイクアクセスが発生するシステムなどの場合は、クラウドを提案する良いチャンスだったりもします。
このブログではそのようなニーズを満たすクラスターを運用するときに気を付けたいことや、私自身が検証していて気づいたことをホワイトボードに書く感覚で、だらだらと書きとめます。
なお、本内容はたまたまAzureが提供するKubernetesマネージドサービスである「Azure Kubernetes Service(以下AKS)」を使って検証しましたが、基本的な考え方はやGoogle CloudのGKEやAWSのEKSなど他クラウドでも同じだとおもいます。
クラスターを物理障害から守るアーキテクチャ
Kubernetesはシステムのインフラストラクチャー部分の多くを抽象化しオートヒーリングや宣言ベースのデプロイメントが可能で、高可用性なシステム構築を実現することが可能なコンテナオーケストレータです。 が、その土台をささえる物理レイヤーはオンプレミスやクラウドにかかわらず、まじないや祈祷のたぐいで安定稼働しているわけではありません。
多くの場合ハードウエアはデータセンターに収容され、電源/ネットワーク/冷却装置/サーバー/ストレージなどを構成しているため、高可用性システムを構築するにはSPOF(単一障害点)がないようインフラを設計する必要があります。
またサーバー群にインストールするOSで脆弱性やバグなどが発生したときはバージョンアップなどを行う必要もあります。
AzureのAKSはマネージドサービスではありますが、中でKuberntesのNodeをAzureのVMを使って構成しています。AzureのVMの可用性を高める手法として「可用性ゾーン」というものがあります。
ざっくりってしまうと、たとえばAzureの東日本リージョンにはそれぞれ異なる電源/ネットワーク/冷却装置が別々の3つのデータセンター(ゾーン)があります。そのためアプリを3つのデータセンターで分散して動かしておけば、たとえどこかのデータセンター内で障害が発生しても、システムが継続できる可能性が高くなります。
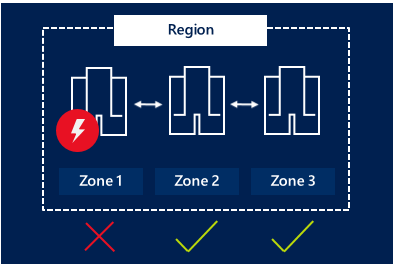
またこの可用性ゾーンは「更新ドメイン」をもっており、メンテナンスや再起動でシステムが停止するリスクを減らすこともできます。
物理的に分散したKubernetesクラスターを作成する
AKSには、可用性ゾーンを使用するKuberntesクラスターを作成することができます。この便利機能を使うと、次のようにKuberntesのNodeを分散して配置できます。

いくつかの制限事項がありますが、執筆時点(2020/02)では、次のリージョンの可用性ゾーンが使用できます。東日本リージョンでも利用できます。
- 米国中部
- 米国東部 2
- 米国東部
- フランス中部
- 東日本
- 北ヨーロッパ
- 東南アジア
- 英国南部
- 西ヨーロッパ
- 米国西部 2
ゾーンの停止時、つまりデータセンター丸ごと障害時には、手動またはオートスケーラーを使用してNodeを再調整でき、たとえ1つのゾーンが使用不可になっても、アプリケーションは引き続き実行されます。
AKSクラスターの構築のしかたは公式ドキュメントのとおりですが、ポイントとしては以下のように、az aks createコマンドの引数に --zonesオプションを指定します。これで3つのゾーンにNodeが分散されます。
az aks create \ -g $RG_NAME \ -n $AKS_NAME \ --generate-ssh-keys \ --vm-set-type VirtualMachineScaleSets \ --load-balancer-sku standard \ --node-count 3 \ --zones 1 2 3
※ 今回は検証のためなので、--generate-ssh-keysオプションを指定していますが、本番環境ではきちんとSSH Keyを設定してください。
クラスターは約15分ほどで起動します。次のコマンドでNodeが分散されているのを確認してください。3台のNodeが東日本リーションのjapaneast-1/japaneast-2/japaneast-3にそれぞれ1台ずつ配置されているのが分かります。
$ kubectl describe nodes | grep -e "Name:" -e "failure-domain.beta.kubernetes.io/zone" 1:Name: aks-nodepool1-30480082-vmss000000 8: failure-domain.beta.kubernetes.io/zone=japaneast-1 95:Name: aks-nodepool1-30480082-vmss000001 102: failure-domain.beta.kubernetes.io/zone=japaneast-2 187:Name: aks-nodepool1-30480082-vmss000002 194: failure-domain.beta.kubernetes.io/zone=japaneast-3

アプリのデプロイ
「物理的」に高可用性なクラスターが立ち上がったところで、3種類のサンプルアプリをデプロイしてみます。
技術ブログだと「SampleA」「SampleB」「SampleC」をデプロイすれば十分に説明可能ですが、より臨場感と危機感を出すために以下の名前のアプリをデプロイします。
- shipping: 発送処理
- orders: オーダー受付処理
- payment: 決済処理
なお、サンプルのPodはただのNgnixが立ち上がるだけのものです。レプリカ数は3としました。
現在のNodeの構成は以下のようになっていて、3台がいずれもReadyなのが分かります。
$ kubectl get no NAME STATUS ROLES AGE VERSION aks-nodepool1-30480082-vmss000000 Ready agent 59m v1.14.8 aks-nodepool1-30480082-vmss000001 Ready agent 59m v1.14.8 aks-nodepool1-30480082-vmss000002 Ready agent 59m v1.14.8
ここに対して、次のコマンドでDaploymentをapplyします。
$ kubectl apply -f orders-dep.yaml $ kubectl apply -f payment-dep.yaml $ kubectl apply -f shipping-dep.yaml
「aks-nodepool1-30480082-vmss000000」「aks-nodepool1-30480082-vmss000001」「aks-nodepool1-30480082-vmss000002」に分散されて、Podがスケジューリングされているのがわかります。
$ kubectl get po --output wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES orders-64db48bc-cdccd 1/1 Running 0 19m 10.244.2.2 aks-nodepool1-30480082-vmss000002 <none> <none> orders-64db48bc-grg7c 1/1 Running 0 11m 10.244.0.8 aks-nodepool1-30480082-vmss000000 <none> <none> orders-64db48bc-rj9b2 1/1 Running 0 19m 10.244.1.2 aks-nodepool1-30480082-vmss000001 <none> <none> payment-c7ddbf474-dsxb6 1/1 Running 0 19m 10.244.1.3 aks-nodepool1-30480082-vmss000001 <none> <none> payment-c7ddbf474-fjjfb 1/1 Running 0 19m 10.244.2.3 aks-nodepool1-30480082-vmss000002 <none> <none> payment-c7ddbf474-j5fmp 1/1 Running 0 11m 10.244.0.9 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-dq7b4 1/1 Running 0 10m 10.244.0.10 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-jrnk5 1/1 Running 0 18m 10.244.2.4 aks-nodepool1-30480082-vmss000002 <none> <none> shipping-6748cd9766-z65xs 1/1 Running 0 18m 10.244.1.4 aks-nodepool1-30480082-vmss000001 <none> <none>

これでバランスよく、3台のNodeに3種類アプリが1個づつ分散されて配置されました。
しつこいですが、この3台のNodeは物理的には別々のデータセンターにいるので、データセンターのいずれかが障害になってもなんとか他のNodeで処理をサービスを継続できます。
スケーラブルなクラスターの運用
さて、ここからが少しシステムの設計として頭を使って考えないといけないことが始まります。
AKSにはクラスターのNodeをスケールする機能があります。利用者が少ない時はクラスターのNodeを減らしておくことでコスト最適化ができます。たとえば、手動でNodeを1台に減らすには次のコマンドを実行します。
az aks scale -g $RG_NAME -n $AKS_NAME --node-count 1 --nodepool-name nodepool1
これにより、3台構成だったNodeが1台に減りました。
AKSではクラスタオートスケーラーを使ってシステムの負荷に応じてNodeの台数を増減させることもできます。
なにが問題か?
現在の構成を確認してみます。
$ kubectl get no NAME STATUS ROLES AGE VERSION aks-nodepool1-30480082-vmss000000 Ready agent 95m v1.14.8
現時点でorder/payment/shippingのすべてのPodは、Kuberntesのオートヒーリングの機能で稼働しているNode「aks-nodepool1-30480082-vmss000000」上にデプロイされているのが分かります。
$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES orders-64db48bc-grg7c 1/1 Running 0 33m 10.244.0.8 aks-nodepool1-30480082-vmss000000 <none> <none> orders-64db48bc-jzlmc 1/1 Running 0 6m31s 10.244.0.13 aks-nodepool1-30480082-vmss000000 <none> <none> orders-64db48bc-vghdh 1/1 Running 0 6m31s 10.244.0.14 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-9dctq 1/1 Running 0 6m31s 10.244.0.15 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-j5fmp 1/1 Running 0 33m 10.244.0.9 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-v2cz7 1/1 Running 0 6m31s 10.244.0.16 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-9gtds 1/1 Running 0 6m31s 10.244.0.12 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-dq7b4 1/1 Running 0 32m 10.244.0.10 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-rzjsh 1/1 Running 0 6m31s 10.244.0.11 aks-nodepool1-30480082-vmss000000 <none> <none>

Nodeが可用性ゾーンに分散された3台構成から、1台構成に減ったわけなので、この状態で現状動いている1台「aks-nodepool1-30480082-vmss000000」が止まればシステム全停止になるのは、直感的に理解できます。
Nodeをスケールしよう!
というわけで、Nodeを1台から元の3台構成に増やします。
az aks scale -g $RG_NAME -n $AKS_NAME --node-count 3 --nodepool-name nodepool1
構成を見てみます。きちんと3台構成になっています。
kubectl get no NAME STATUS ROLES AGE VERSION aks-nodepool1-30480082-vmss000000 Ready agent 104m v1.14.8 aks-nodepool1-30480082-vmss000003 Ready agent 98s v1.14.8 aks-nodepool1-30480082-vmss000004 Ready agent 100s v1.14.8
どのゾーンにNodeが配置されているのかも確認します。Azureが責任をもって3台を「japaneast-1」「japaneast-2」「japaneast-3」の3つのゾーンにNodeを分散させています。
kubectl describe nodes | grep -e "Name:" -e "failure-domain.beta.kubernetes.io/zone" 1:Name: aks-nodepool1-30480082-vmss000000 8: failure-domain.beta.kubernetes.io/zone=japaneast-1 93:Name: aks-nodepool1-30480082-vmss000003 100: failure-domain.beta.kubernetes.io/zone=japaneast-2 183:Name: aks-nodepool1-30480082-vmss000004 190: failure-domain.beta.kubernetes.io/zone=japaneast-3
めでたし。これで高可用性、かつスケーラブルなシステムに戻ったーー。
...
...
...
とはならないので注意が必要です。
次のコマンドでPodの配置を確認してみます。
$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES orders-64db48bc-grg7c 1/1 Running 0 42m 10.244.0.8 aks-nodepool1-30480082-vmss000000 <none> <none> orders-64db48bc-jzlmc 1/1 Running 0 15m 10.244.0.13 aks-nodepool1-30480082-vmss000000 <none> <none> orders-64db48bc-vghdh 1/1 Running 0 15m 10.244.0.14 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-9dctq 1/1 Running 0 15m 10.244.0.15 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-j5fmp 1/1 Running 0 41m 10.244.0.9 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-v2cz7 1/1 Running 0 15m 10.244.0.16 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-9gtds 1/1 Running 0 15m 10.244.0.12 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-dq7b4 1/1 Running 0 41m 10.244.0.10 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-rzjsh 1/1 Running 0 15m 10.244.0.11 aks-nodepool1-30480082-vmss000000 <none> <none>

このようにorder/shipping/paymentのすべてのPodが「aks-nodepool1-30480082-vmss000000」におり、微動だにしていないのです。
ということは、現時点で運悪く「aks-nodepool1-30480082-vmss000000」に障害が発生してしまうと、システムが全停止します。
あらためて冷静に考えると
- 可用性ゾーンに従い、Nodeは地理的に分散されている
- にもかかわらず、アプリケーションは1台に偏ってデプロイされている
ということがおこっています。可用性ゾーンは物理Nodeにデプロイされるアプリが決まっている、トラディショナルなIaaSベースのアプリケーションアーキテクチャであれば有効に働きます。が、Kuberntesはその物理レイヤーの上に抽象化したレイヤーがあり、アプリケーションのスケジューリングをクラスターのコントロールプレーンがアルゴリズムに基づき自動的にデプロイされます。
つまり、アーキテクチャとして物理的な可用性と論理的な可用性を考慮しなければいけないということが分かります。
アプリケーションがアップデードしたときは、どうスケジューリングされるか?
もうちょっと深堀りしてみていきます。
現在、Nodeの1台にすべてのアプリがデプロイされているわけなのですが、そこはKuberntes。
利用者する際はCI/CDパイプラインががっちり整備されており、常にアプリケーションの継続的デプロイメントが発生するものとします。
ここでアプリ開発チームが「shipping」と「order」のアプリケーションをバージョンアップするパイプラインを実行したと仮定します。
$ kubectl apply -f orders-dep.yaml $ kubectl apply -f shipping-dep.yaml
すると、新しい「shipping」と「order」のPodがクラスターにデプロイされます。
Podの状態を確認してみましょう!!
新しい「shipping」と「order」はみごとに3台のNodeにきちんと分散されてデプロイされました。
$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES orders-56d5d9769f-gxvsl 1/1 Running 0 43s 10.244.0.17 aks-nodepool1-30480082-vmss000000 <none> <none> orders-56d5d9769f-n5w2t 1/1 Running 0 54s 10.244.3.2 aks-nodepool1-30480082-vmss000004 <none> <none> orders-56d5d9769f-r9ztr 1/1 Running 0 54s 10.244.4.2 aks-nodepool1-30480082-vmss000003 <none> <none> payment-c7ddbf474-9dctq 1/1 Running 0 35m 10.244.0.15 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-j5fmp 1/1 Running 0 62m 10.244.0.9 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-v2cz7 1/1 Running 0 35m 10.244.0.16 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-7954d7c6f8-27bw2 1/1 Running 0 37s 10.244.0.18 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-7954d7c6f8-d5lr9 1/1 Running 0 39s 10.244.3.3 aks-nodepool1-30480082-vmss000004 <none> <none> shipping-7954d7c6f8-whsxd 1/1 Running 0 39s 10.244.4.3 aks-nodepool1-30480082-vmss000003 <none> <none>

が、、、、しかし。
アプリケーションの更新がかからなかった「payment」のPodは3つとも引き続き「aks-nodepool1-30480082-vmss000000」にのみデプロイされたままです。
現時点で「aks-nodepool1-30480082-vmss000000」が何らか障害が発生すると、paymentつまり決済処理のアプリケーションが一切機能しないということが、起こりえます。
しょぼん。悲しい。
KubernetesはどのようにPodをスケジューリングするのか?
なぜ、このような動きをするのでしょうか?今回の挙動を、Kuberntesのしくみ目線で見ていきます。
まず大前提として知っておきたいのが、Kubernetesのスケジューリングの方式についてです。

Kubernetesのコントロールプレーン
ここでクラスターを管理するKubernetesのコントロールプレーンのしくみについてみていきます。
Kubernetesは分散環境でサーバ群が協調してそれぞれの処理を行います。このかたまりのことをKubernetesクラスターと呼びます。Kubernetesで動作しているサーバおよび主なコンポーネントは次のとおりです。

Master
Kubernetesクラスター内のコンテナを操作するためのサーバです。kubectlコマンドを使ってクラスターを構成したりリソースを操作したりする際は、マスターサーバがコマンドからのリクエストを受け取って処理を行います。複数台からなるKubernetesクラスター内のNodeのリソース使用状況を確認して、コンテナを起動するNodeを自動的に選択します。Kubernetesがオーケストレーションツールと呼ばれるのも、このマスターサーバが複数台からなる分散したNodeをまとめて管理することで、あたかも1台のサーバであるかのようにふるまいます。
kube-apiserver
Kubernetesのリソース情報を管理するためのフロントエンドのREST APIです。各コンポーネントからリソースの情報を受け取りetcd上に格納します。他のコンポーネントはこのetcdの情報にkube-apiserverを介してアクセスします。このkube-apiserverにアクセスするには、GUIツールやkubebtlコマンドを使います。また、アプリケーション内からkube-apiserverを呼び出すことも可能です。kube-apiserverは認証/認可の機能も持っています。
kube-scheduler
kube-schedulerはPodをどのNodeで動かすかを制御するコンポーネントです。kube-schedulerは、Nodeに割り当てられていないPodに対して、Kubernetesクラスターの状態を確認し、空きスペースを持つNodeを探してPodを実行させるスケジューリングを行います。
kube-controller-manager
kube-controller-managerはKubernetesクラスターの状態を常に監視するコンポーネントです。定義ファイルで指定したものと実際のNodeやコンテナーで動作している状態をまとめて管理します。
etcd
Kubernetesクラスターの構成を保持する分散KVSです。Key-Value型でデータを管理します。どのようなPodをどう配置するかなどの情報を持ち、API Serverから参照されます。
Node
実際にコンテナーを動作させPodを稼働させるサーバです。AKSでは仮想マシン(VM)で構成され、通常は複数用意して、クラスターを構成します。Nodeの管理は、マスターサーバが行います。何台Nodeを用意するかは、システムの規模や負荷によって異なりますが台数が増えると可用性が向上します。なお、kubeproxyというコンポーネントも動作しますが、今回は長くなるので説明は省略。
kubelet
kubeletは、Podの定義ファイルに従ってコンテナーを実行したり、ストレージをマウントしたりするエージェント機能を持ちます。またKubeletは、Nodeのステータスを定期的に監視する機能を持ちステータスが変わるとAPI Serverに通知します。
Kubernetesスケジューラーのしくみ
クラスターの状態監視は、Masterのkube-controller-managerが行います。このkube-controller-managerには次の機能があります。
- ReplicationManager
- ReplicaSet/DaemonSet/Job controllers
- Deployment controller
- StatefulSet controller
- Node controller
- Service controller
- Endpoint controller
- Namespace controller etc
この中でPodの状態はReplicationManagerが監視しています。もし、実際に稼働しているPodの数とetcdで管理しているマニュフェストファイルで定義したreplicasの数が一致していない場合は、Podの数を調整します。
その際、kube-schedulerによって最適なNodeにPodがスケジューリングされます。実際に、Node上にPodを実行させるのは、kubeletが行います。kubeletは自Nodeに割り当てられた必要な数のPodを立ち上げます。

では、このときの「③ Podを割り当てるNodeの選定」はどうやって決まるのでしょうか?
Podのスケジューリング
Kubernetesでは、大きく分けて次の2つのルールでPodのスケジューリング先を決めます。
Nodeフィルタリング
PodにNodeSelectorを設定しているかどうかやPodに設定されたリソース要求と実際のリソースの空き状況などを見て割り当てるNodeを決めます。
たとえば、あるNodeにラベルを設定しておき、ラベルの付いたNodeにPodを意図的にデプロイする、などの制御ができます。利用用途としては、クラスター内にGPUをもつインスタンスを立ち上げておき、おもたい計算処理を行うPodをGPUインスタンスに割り当てる、などがあります。あとは優先度の低いPodを低価格なプリエンプティブVMで動かし、クラスター全体のコンピューティングリソース使用率を上げたい、などもこれで実現できます。

※ 今回のサンプルでは、PodにNodeSelectorは設定していません。
Nodeの優先付け
同じ種類のPodができる限り複数のNodeに分散するようにしたり、CPUとメモリの使用率のバランスをとるような優先度をつけたりできます。これらにより、なるべく特定のNodeにかたよらないようバランスを見ながらスケジューリングできることが分かります。
| 値 | 説明 |
|---|---|
| SelectorSpreadPriority | 同一のService、StatefulSetや、ReplicaSetに属するPodを複数のホストをまたいで稼働させる |
| InterPodAffinityPriority | weightedPodAffinityTermの要素をイテレートして合計を計算したり、もし一致するPodAffinityTermがNodeに適合している場合は、”重み”を合計値に足す。最も高い合計値を持つNode(複数もあり)が候補となる |
| LeastRequestedPriority | 要求されたリソースがより低いNodeを優先 |
| MostRequestedPriority | 要求されたリソースがより多いNodeを優先 |
| RequestedToCapacityRatioPriority | デフォルトのリソーススコアリング関数を使用して、requestedToCapacityベースのResourceAllocationPriorityを作成する |
| BalancedResourceAllocation | バランスのとれたリソース使用量になるようにNodeを選択 |
| NodePreferAvoidPodsPriority | Nodeのscheduler.alpha.kubernetes.io/preferAvoidPodsというアノテーションに基づいてNodeの優先順位づけ行う |
| NodeAffinityPriority | PreferredDuringSchedulingIgnoredDuringExecutionの値によって示されたNode Affinityのスケジューリング性向に基づいてNodeの優先順位づけを行う |
| TaintTolerationPriority | Node上における許容できないTaintsの数に基づいて、全てのNodeの優先順位リストを準備する。このポリシーでは優先順位リストを考慮してNodeのランクを調整 |
| ImageLocalityPriority | すでにPodに対するコンテナイメージをローカルにキャッシュしているNodeを優先 |
| ServiceSpreadingPriority | 特定のServiceに対するバックエンドのPodが、それぞれ異なるNodeで実行されるようにすることです。このポリシーではServiceのバックエンドのPodが既に実行されていないNode上にスケジュールするように優先します。これによる結果として、Serviceは単体のNode障害に対してより耐障害性が高まります。 |
| CalculateAntiAffinityPriorityMap | このポリシーはPodのAnti-Affinityの実装に必要 |
| EqualPriorityMap | 全てのNodeに対して等しい重みを与える |
さらにアルゴリズムにご興味ある人はぜひ! Scheduler Algorithm in Kubernetes
AKSの場合はどうなってるか
AKSのドキュメント-複数のゾーンへのポッドの分散を確認するをみると、failure-domain.beta.kubernetes.io/zoneラベルを使用して、使用可能なゾーンにわたってPodを自動的に分散します。と書かれています。
failure-domain.beta.kubernetes.io/zone=zone名
さらに、こちらのGitHubのissueをみるとAKSがスケーリング時にNode間でゾーンに基づくスケジューリングをサポートしているかどうかが議論されていることもわかります。 具体的には上記のラベルを見てSelectorSpreadPriorityにもとづき"best effort"で分散してデプロイさせていることを、うかがい知ることができます。
これをふまえてさきほど、私が実験したときを思い返します。
まずはじめに「shipping」「order」「Payment」をクラスターにデプロイしたとき、3種類×3個のPodがバラバラに配置されていたのがわかります。
$ kubectl get po --output wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES orders-64db48bc-cdccd 1/1 Running 0 19m 10.244.2.2 aks-nodepool1-30480082-vmss000002 <none> <none> orders-64db48bc-grg7c 1/1 Running 0 11m 10.244.0.8 aks-nodepool1-30480082-vmss000000 <none> <none> orders-64db48bc-rj9b2 1/1 Running 0 19m 10.244.1.2 aks-nodepool1-30480082-vmss000001 <none> <none> payment-c7ddbf474-dsxb6 1/1 Running 0 19m 10.244.1.3 aks-nodepool1-30480082-vmss000001 <none> <none> payment-c7ddbf474-fjjfb 1/1 Running 0 19m 10.244.2.3 aks-nodepool1-30480082-vmss000002 <none> <none> payment-c7ddbf474-j5fmp 1/1 Running 0 11m 10.244.0.9 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-dq7b4 1/1 Running 0 10m 10.244.0.10 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-6748cd9766-jrnk5 1/1 Running 0 18m 10.244.2.4 aks-nodepool1-30480082-vmss000002 <none> <none> shipping-6748cd9766-z65xs 1/1 Running 0 18m 10.244.1.4 aks-nodepool1-30480082-vmss000001 <none> <none>

次にアプリを更新した「shipping」と「order」も3台のNodeにきちんと分散されてデプロイされました。
$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES orders-56d5d9769f-gxvsl 1/1 Running 0 43s 10.244.0.17 aks-nodepool1-30480082-vmss000000 <none> <none> orders-56d5d9769f-n5w2t 1/1 Running 0 54s 10.244.3.2 aks-nodepool1-30480082-vmss000004 <none> <none> orders-56d5d9769f-r9ztr 1/1 Running 0 54s 10.244.4.2 aks-nodepool1-30480082-vmss000003 <none> <none> shipping-7954d7c6f8-27bw2 1/1 Running 0 37s 10.244.0.18 aks-nodepool1-30480082-vmss000000 <none> <none> shipping-7954d7c6f8-d5lr9 1/1 Running 0 39s 10.244.3.3 aks-nodepool1-30480082-vmss000004 <none> <none> shipping-7954d7c6f8-whsxd 1/1 Running 0 39s 10.244.4.3 aks-nodepool1-30480082-vmss000003 <none> <none>

これは、AKSのコントロールプレーンがPodをスケジューリングする際に、Nodeに設定されたfailure-domain.beta.kubernetes.ioを考慮したと考えることができます。
kube-deschesulerでPodを再スケジュール
Kubernetesは非常に高度なしくみを用いて、物理Nodeを意識しながらPodを分散させてデプロイされているということがわかりましたが、なぜ今回はのアプリのみ分散されずに「aks-nodepool1-30480082-vmss000000」にだけ偏ってしまったのでしょうか?
それは、KubernetesのスケジューラーはPodがなんらかの理由で削除されない限り、Node間でPodを移動しないためです。
あらためてpayment Pod目線で冷静に挙動を見直してみます。
まず、payment Podは初回のデプロイ時、AKSによりバランスよく3つのゾーンに分散して配置されました。その後クラスターのNode数が1台に縮退されたため、やむを得ず1台のNodeにPodが集まりました。さらにその後Podの更新がなかったため、上記の原則にしたがいNode間でPodを移動することなく、3つのPodとも「aks-nodepool1-30480082-vmss000000」にとどまり続けたのです。
このPodの偏りを平準化するためkube-deschesulerというものがあります。
このkube-deschesulerは一部のNodeが使用されているか、使用されていない場合や一部のNodeに障害が発生し、Podが他のNodeに移動し、Podが偏ったときに移動可能なポッドを見つけて削除するものです。削除されたPodはKubernetesの通常のスケジューラによって再スケジュールされます。
kube-deschesulerはKubernetesのJobまたはCronJobとして動作します。1回だけさっぱり整えたい!というときはJob、定期的にチェックして綺麗にしたい場合はCronJobにすればよいでしょう。
今こんな感じでpayment Podが「aks-nodepool1-30480082-vmss000000」にかたまっています。
$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES payment-c7ddbf474-9dctq 1/1 Running 0 4h51m 10.244.0.15 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-j5fmp 1/1 Running 0 5h18m 10.244.0.9 aks-nodepool1-30480082-vmss000000 <none> <none> payment-c7ddbf474-v2cz7 1/1 Running 0 4h51m 10.244.0.16 aks-nodepool1-30480082-vmss000000 <none> <none>
deschedulerのGitHubのReadme.mdにしたがってクラスターにデプロイします。
$ git clone git@github.com:kubernetes-sigs/descheduler.git $ kubectl create -f kubernetes/rbac.yaml $ kubectl create -f kubernetes/configmap.yaml $ kubectl create -f kubernetes/job.yaml
kube-system名前空間にJobがデプロイされます。
k get job -n kube-system NAME COMPLETIONS DURATION AGE descheduler-job 1/1 9s 2m52s
そして、payment Podの状況を見てみましょう。偏っていたPodがゾーンをまたがるNodeに分散されてデプロイされました。この状態であれば、いずれかのゾーンが全停止したとしても、他のゾーンでサービスを継続できることがわかります。
$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES payment-c7ddbf474-64ws9 1/1 Running 0 2m14s 10.244.3.4 aks-nodepool1-30480082-vmss000004 <none> <none> payment-c7ddbf474-86p7r 1/1 Running 0 2m14s 10.244.4.5 aks-nodepool1-30480082-vmss000003 <none> <none> payment-c7ddbf474-9dctq 1/1 Running 0 5h32m 10.244.0.15 aks-nodepool1-30480082-vmss000000 <none> <none>
kube-deschesulerのしくみ
この、kube-deeschedulerはどういう方法でかたよりを無くすかを決めることができます。全部で5つほどありますが、よく使われそうな2つを説明します。
RemoveDuplicates
同じReplicaSetから作られたPodが、ひとつのNodeに複数配置されていた場合にPodを削除します。kube-scheduler先ほど説明したSelectorSpreadPriorityというNodeやゾーンに対して分散させるpriorityがあるため、Podを削除することで複数Nodeに分散させます。
これを無効化したいときは、次のように設定します。
apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "RemoveDuplicates": enabled: false
LowNodeUtilization
リソースの利用率が高いNodeのPodをリソース利用率が低いNodeに再スケジュールします。リソースの使用率はCPU/メモリの状況、動いているPodの数を閾値として定義します。
実際のマニュフェストをみると雰囲気が分かりやすいと思います。
apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "LowNodeUtilization": enabled: true params: nodeResourceUtilizationThresholds: thresholds: "cpu" : 20 "memory": 20 "pods": 20 targetThresholds: "cpu" : 50 "memory": 50 "pods": 50
その他AntiAffinityに反しているPodを削除したりなどもできます。
なお、kube-deschesulerではPodはevictionのしくみを使って削除されるため、PodDisruptionBudgetの設定が考慮されます。そして、PodのQosClassがBestEffortのものは/Bustrable/Guaranteedより先に削除されるというルールもあります。
またkube-deschesulerは、以下のPodの削除の対象外となります。
- priorityClassNameが
system-cluster-criticalまたはsystem-node-criticalに設定されているPod - Deploymemt/ReplicaSet/Jobなどで管理されていないPod
- DaemonSetが作成したPod
- Local Storageを利用したPod
冷静に考えれば当然ですが、DaemonSetが消されちゃったら困りますし、ストレージをマウントしているPodも要注意です。
おわりに
とりとめのないだらだら長いブログになってしまいましたが、人類が実現したいことは「どこかしらで障害があったとしても、サービスを継続し続けること」「スケーラブルな基盤がほしい」です。
そのための処理方式の1つとして、複数のデータセンターをまたいだ構成でKubernetesクラスターを物理的に分けて構築するというのを検討しましたが、考慮が必要でした。
そもそも、今回の実験の中盤でKubernetesクラスターのNodeの数を1台にしました。当たり前ですが、これをやらなければPodが不必要に偏ることもありませんでしたし、kube-deschesulerに頼る必要もなかったわけです。
いずれにせよ今回検証したようなパターンでの挙動は物理的なシステム構成だけでなく、Kubernetesのなかの論理的なしくみを理解していないといけません。
というわけで、高い可用性が求められ、かつNodeの数の少ない小さなクラスターを運用するときは注意が必要です。
また、今回のブログではディザスタリカバリーのことはまったく触れていませんが、たとえばAzureの場合だとAzure Kubernetes Service (AKS) での事業継続とディザスター リカバリーに関するベスト プラクティスというガイドも公開されています。
すこし脱線ですが、Kubernetesを導入する際のアーキテクチャ設計は難しい問題です。可用性や拡張性などの設計ももちろんですが、クラスター内で動くアプリケーションの機能要件も考慮が必要です。技術的な観点だけでなく開発体制やスタイルなど組織構造も検討しなければいけません。AKSの場合、実践的なベストプラクティスが公式ドキュメントにまとまっています。
さらに、あるクラウドがすべてダウンというケースもあり得ると思います。その際は、複数のクラウドやオンプレミスとのフェデレーションも検討が必要です。
というわけで、わたしのクラウドジャーニーは続くわけです。
みなさま、手洗いとうがいは忘れずに。